
Publications
Home Publications
Home Publications
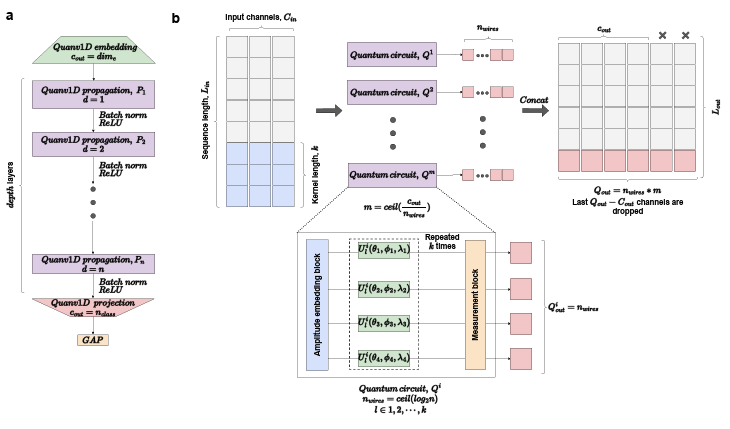
Despite the advancements in quantum convolution or quanvolution, challenges persist in making quanvolution scalable, efficient, and applicable to multi-dimensional data. Existing quanvolutional networks heavily rely on classical layers, with minimal quantum involvement due to inherent limitations in current quanvolution algorithms. Moreover, the application of quanvolution in the domain of 1D data remains largely unexplored. To address these limitations, we propose a new quanvolution algorithm-Quanv1D-capable of processing arbitrary-channel 1D data, handling variable kernel sizes, and generating a customizable number of feature maps, along with a classification network-fully quanvolutional network (FQN)-built solely using Quanv1D layers. Quanv1D is inspired by the classical Conv1D and stands out from the quanvolution literature by being fully trainable, modular, and freely scalable with a self-regularizing feature. To evaluate FQN, we tested it on 20 UEA and UCR time series datasets, both univariate and multivariate, and benchmarked its performance against state-of-the-art convolutional models (both quantum and classical). We found FQN to outperform all compared models in terms of average accuracy while using significantly fewer parameters. Additionally, to assess the viability of FQN on real hardware, we conducted a shot-based analysis across all the datasets to simulate statistical quantum noise and found our model robust and equally efficient.
Full Article
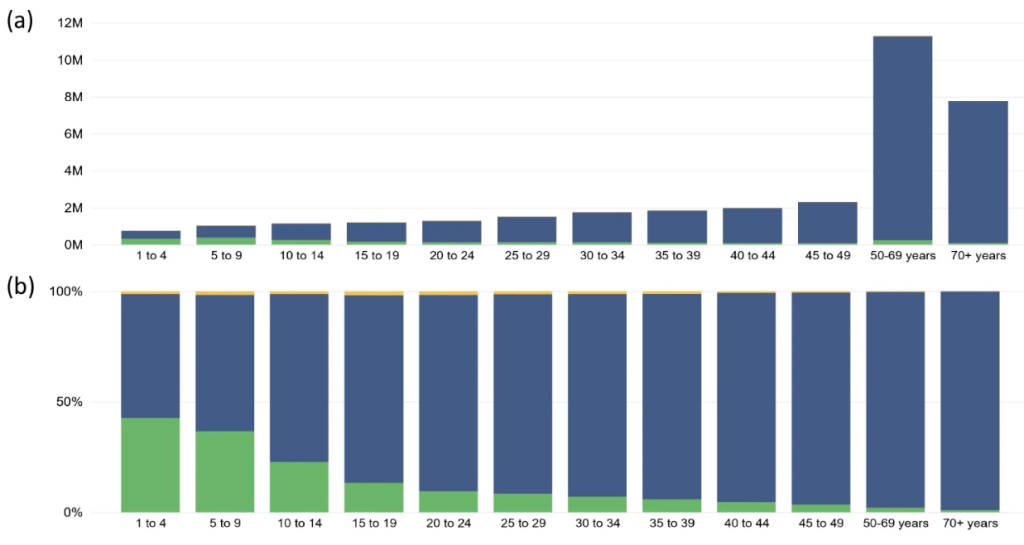
Chronic care manages long-term, progressive conditions, while acute care addresses short-term conditions. Chronic conditions increasingly strain health systems, which are often unprepared for these demands. This study examines the burden of conditions requiring acute versus chronic care, including sequelae. Conditions and sequelae from the Global Burden of Diseases Study 2019 were classified into acute or chronic care categories. Data were analysed by age, sex, and socio-demographic index, presenting total numbers and contributions to burden metrics such as Disability-Adjusted Life Years (DALYs), Years Lived with Disability (YLD), and Years of Life Lost (YLL). Approximately 68% of DALYs were attributed to chronic care, while 27% were due to acute care. Chronic care needs increased with age, representing 86% of YLDs and 71% of YLLs, and accounting for 93% of YLDs from sequelae. These findings highlight that chronic care needs far exceed acute care needs globally, necessitating health systems to adapt accordingly.
Full Article
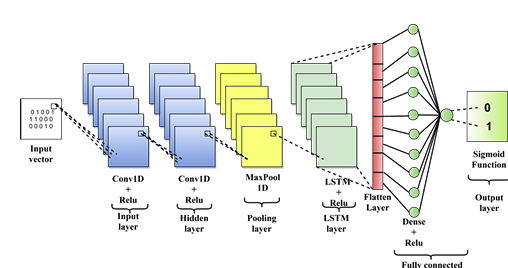
To prevent different chemicals from entering the brain, the blood-brain barrier penetrating peptide (3BPP) acts as a vital barrier between the bloodstream and the central nervous system (CNS). This barrier significantly hinders the treatment of neurological and CNS disorders. 3BPP can get beyond this barrier, making it easier to enter the brain and essential for treating CNS and neurological diseases and disorders. Computational techniques are being explored because traditional laboratory tests for 3BPP identification are costly and time-consuming. In this work, we introduced a novel technique for 3BPP prediction with a hybrid deep learning model. Our proposed model, Deep3BPP, leverages the LSA, a word embedding method for peptide sequence extraction, and integrates CNN with LSTM (CNN-LSTM) for the final prediction model. Deep3BPP performance metrics show a remarkable accuracy of 97.42%, a Kappa value of 0.9257, and an MCC of 0.9362. These findings indicate a more efficient and cost-effective method of identifying 3BPP, which has important implications for researchers in the pharmaceutical and medical industries. Thus, this work offers insightful information that can advance both scientific research and the well-being of people overall.
Full Article
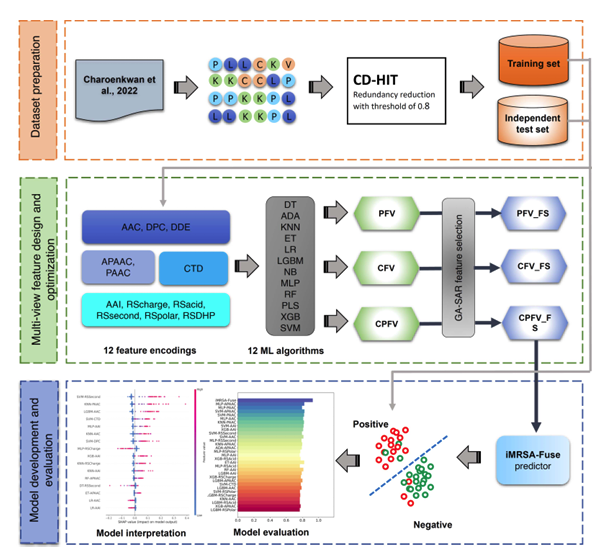
Methicillin-resistant S. aureus (MRSA) has prominently emerged among the recognized causes of community-acquired and hospital infections. We proposed a novel computational approach, iMRSA-Fuse, based on a multi-view feature fusion strategy for fast and accurate anti-MRSA peptide identification. In iMRSA-Fuse, we explored and integrated 12 different sequence-based feature descriptors from multiple perspectives, in conjunction with 12 popular machine learning (ML) algorithms, to construct multi-view features that were able to fully capture the useful information of anti-MRSA peptides. Additionally, we applied our customized genetic algorithm to determine a set of multi-view features to enhance its discriminative ability. Based on a series of comparative results, our multi-view features exhibited the most discriminative ability compared to several conventional feature descriptors. Moreover, concerning the independent test dataset, iMRSA-Fuse achieved the best balanced accuracy (BACC) and Matthew’s correlation coefficient (MCC) of 0.997 and 0.981, respectively with an increase of 3.93 and 7.78%, respectively. Finally, to facilitate the large-scale identification of candidate anti-MRSA peptides, a user-friendly web server of the iMRSA-Fuse model is constructed and is freely accessible at https://pmlabqsar.pythonanywhere.com/iMRSA-Fuse. We anticipate that this new computational approach will be effectively applied to screen and prioritize candidate peptides that might exhibit the great anti-MRSA activities.
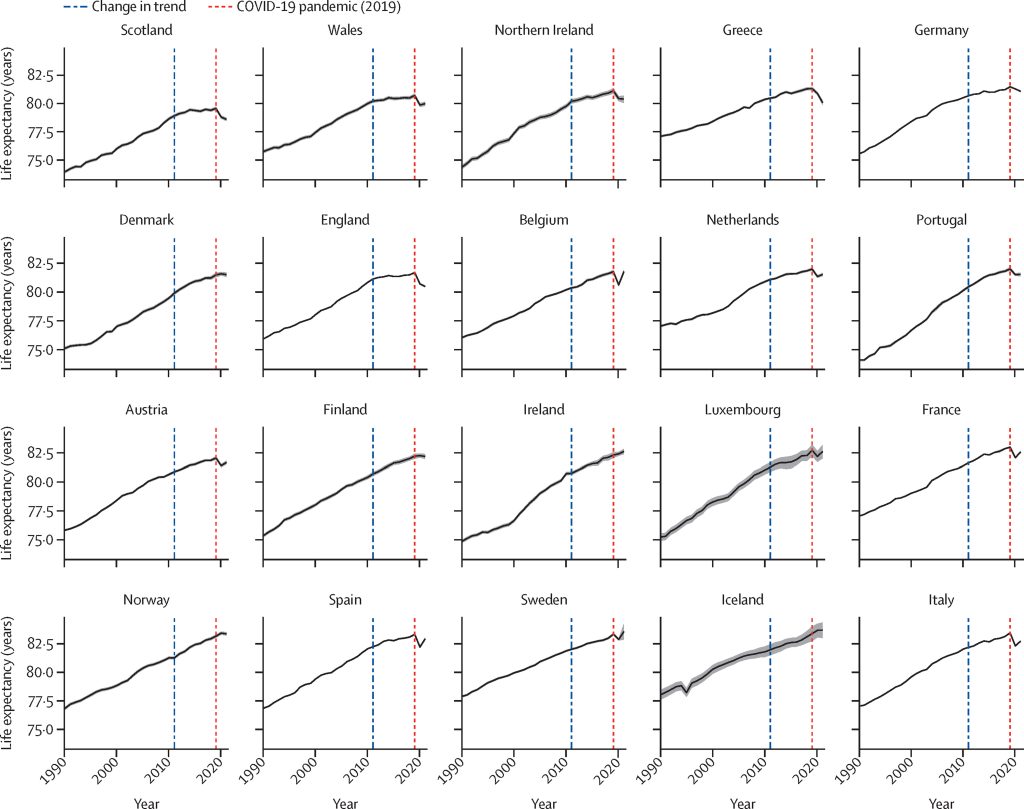
Decades of steady improvements in life expectancy in Europe slowed down from around 2011, well before the COVID-19 pandemic, for reasons which remain disputed. We aimed to assess how changes in risk factors and cause-specific death rates in different European countries related to changes in life expectancy in those countries before and during the COVID-19 pandemic.
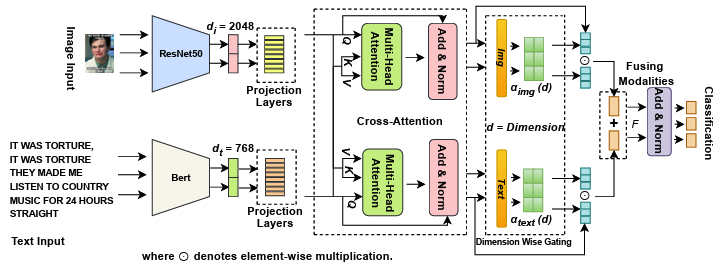
Multimodal sentiment analysis necessitates the seamless integration of textual and visual signals for the precise interpretation of user-generated material. In this paper, we introduce Dimension-Wise Gated Cross-Attention (DGCA). This new fusion mechanism fine-tunes the interaction between language and images more precisely than prior methods. Our method uses a bidirectional cross-attention module to iteratively enhance text and image features. We use a dimension-wise gating technique in which each latent dimension independently learns to weigh contributions from text or image signals using softmax-normalized modality gates. The approach uses selective per-dimension fusion to highlight important cues from one modality while minimizing less useful characteristics from another. On the SemEval-2020 Memotion dataset, DGCA outperformed the state-of-the-art (SOTA) baselines by 2.27%, highlighting its ability to detect subtle affective cues. In summary, DGCA improves performance and interpretability, enabling fine-grained and context-aware multimodal sentiment analysis.
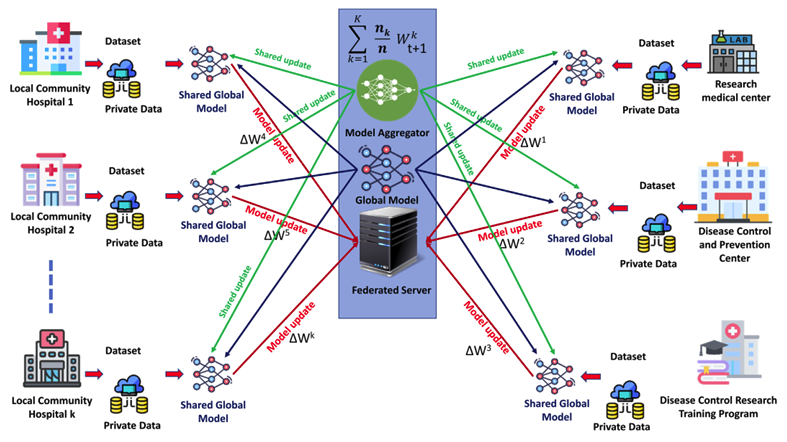
Federated learning (FL) is a privacy-preserving paradigm in distributed machine learning that enables clients to collaboratively train models without sharing their raw data. However, the variety of client data, device setups, and network conditions provides serious difficulties for FL systems. Random client sampling in such environments often leads to suboptimal outcomes, including lower model accuracy, slower convergence rates, and reduced fairness. To address these issues, this study proposes a dynamic client selection mechanism based on a scoring system that evaluates clients based on three key parameters: accuracy, loss, and execution time. We propose a scoring-based framework for adaptive client selection in federated learning (FL) and implement it in an ML-driven diabetes detection system. Evaluations with 200 communication rounds demonstrate improved global and local model performance, faster convergence, and optimized resource utilization. The framework dynamically selects clients, improving execution efficiency and addressing key FL challenges, including data heterogeneity, fairness, communication overhead, and privacy. Our findings highlight its potential for scalable and efficient FL in healthcare applications while paving the way for future advancements in adaptive client selection.
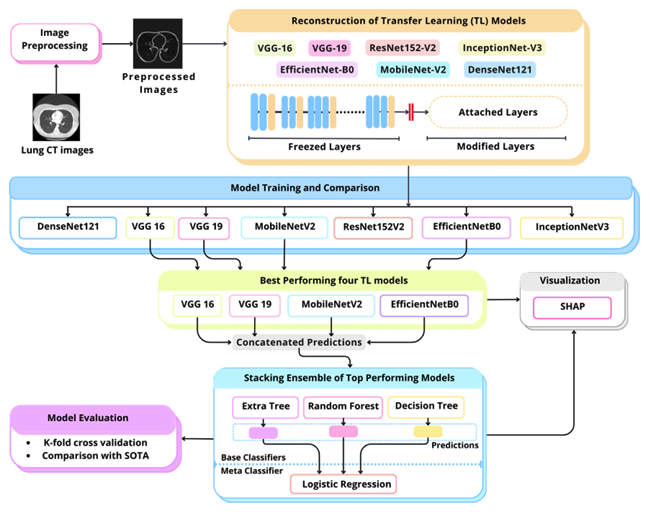
Lung cancer, one of the most prevalent and deadliest diseases, necessitates early detection for patient survival. The low level of contrast between lesions and adjacent lung tissue, coupled with the diverse shapes and structures of lung nodules, poses significant challenges for their accurate identification and classification. Despite the extensive use of machine learning methods, the lack of adequately annotated datasets significantly hampers efficient model training. Moreover, the lack of transparency in deep learning models has led to their perception as “black boxes”, constraining their credibility for end users like radiologists. To address these issues, we present LungCT-NET, a novel transfer learning-based architecture coupled with ensemble learning and explainable AI for binary classification of lung nodules into malignant and benign using lung CT scans. LungCT-NET incorporates essential preprocessing, reconfiguring transfer learning models, and an advanced stacking ensemble strategy utilizing combinations of the top-performing pre-trained models. Several transfer learning algorithms are employed, including VGG-16, VGG-19, MobileNet-V2, InceptionNet-V3, EfficientNet-B0, ResNet152-V2, and DenseNet-121. Extensive experimental analyses have been carried out on the LIDC-DIRI dataset using various performance metrics for evaluation. The findings demonstrate that the suggested framework significantly exceeds state-of-the-art approaches, achieving an accuracy, precision, F1 score and recall of 98.99%, an AUC of 98.15%. Finally, the integrated SHapley Additive exPlanations (SHAP) enhance the grasp of model outcomes, hence increasing confidence in lung cancer prognosis. Therefore, the proposed innovative LungCT-NET can potentially support clinical settings by automating lung nodule classification from low-dose CT scans, aiding physicians and radiologists in prompt, accurate diagnoses.
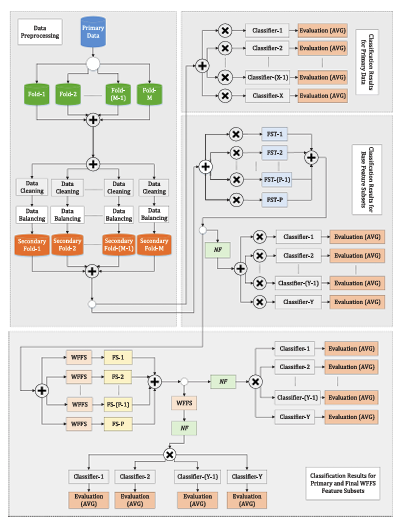
Traffic accidents are unexpected incidents where one or multiple vehicles collide and damage properties, dying or injuring many individuals. It causes significant social burdens, including loss of life, serious injuries, and economic suppression from medical costs, property damages, and productivity losses. This kind of incident brings a miserable situation for the affected people. Many factors, including infrastructure, weather, vehicles, or driver-related issues, contribute to happening traffic accidents. This work explores an innovative approach by investigating contributing factors to ensure road safety. In this study, an ensemble machine learning model, namely Weighted Fusion-Based Feature Selection (WFFS), was proposed to identify different significant features to reduce the effects of traffic accidents. A large amount of traffic accident records from the United Kingdom (UK) were gathered and split into several folds, which were cleaned and balanced using different techniques such as removing percentages, Synthetic Minority Oversampling Technique (SMOTE), and random oversampling. Then, WFFS were employed in each fold and identified the most significant features to predict traffic accident severity more accurately. Different classifiers, such as tree-based, bagging, boosting, and voting classifiers, were implemented into WFFS-generated feature subsets and performed better than primary data and other feature subsets. In this case, the random tree-based bagging method provided the highest accuracy of 97.28% to predict accident severity for the WFFS subset, where its number of features is 18. However, different classifiers achieved better accuracies for 6 out of 11 times using WFFS. This method is highly recommended for policymakers and transportation engineers to identify potentially hazardous locations and take appropriate measures to diminish the effects of traffic accidents.
Full Article
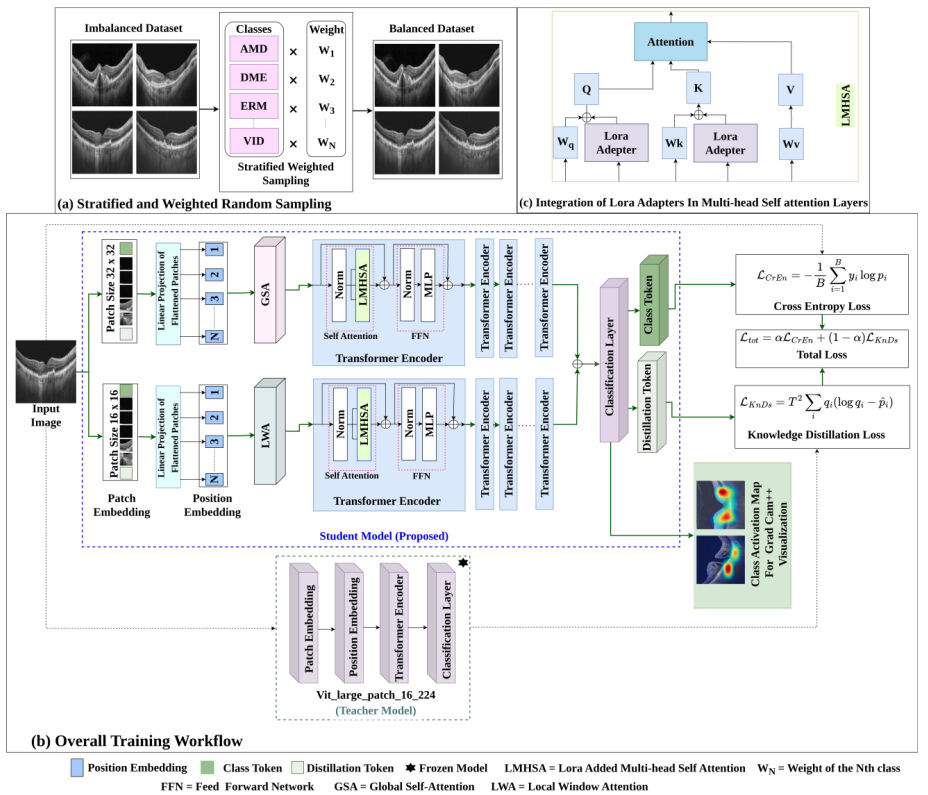
Accurate and privacy-preserving diagnosis of ophthalmic diseases remains a critical challenge in medical imaging, particularly given the limitations of existing deep learning models in handling data imbalance, data privacy concerns, spatial feature diversity, and clinical interpretability. This paper proposes a novel Data efficient Image Transformer (DeiT) based framework that integrates context aware multiscale patch embedding, Low-Rank Adaptation (LoRA), knowledge distillation, and federated learning to address these challenges in a unified manner. The proposed model effectively captures both local and global retinal features by leveraging multi scale patch representations with local and global attention mechanisms. LoRA integration enhances computational efficiency by reducing the number of trainable parameters, while federated learning ensures secure, decentralized training without compromising data privacy. A knowledge distillation strategy further improves generalization in data scarce settings. Comprehensive evaluations on two benchmark datasets OCTDL and the Eye Disease Image Dataset demonstrate that the proposed framework consistently outperforms both traditional CNNs and state of the art transformer architectures across key metrics including AUC, F1 score, and precision. Furthermore, Grad-CAM++ visualizations provide interpretable insights into model predictions, supporting clinical trust. This work establishes a strong foundation for scalable, secure, and explainable AI applications in ophthalmic diagnostics.
Queensland, Australia
+61 414701759, +880 1307195909
neurontree.genai@gmail.com